

Python模块一
推荐教材:
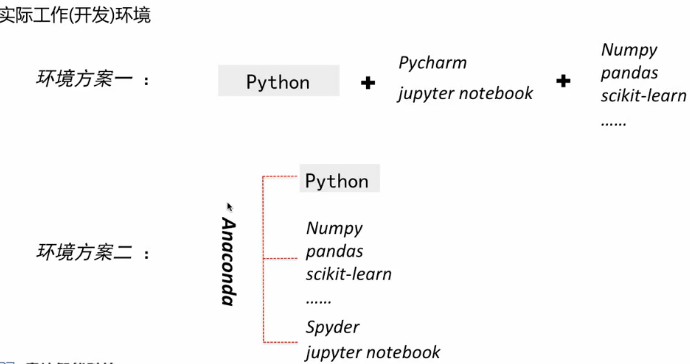
开发环境:


Python模块一
推荐教材:
开发环境:
打开文件
f = open('文件路径/文件名.type','r')
书写路径时
/在python中是转移字符
或者在路径前+r
txe=f.read()
f.close
字典的键值对
dic={i:i**2 for i in range()}
断句取词
words=lyric.split()
大写切换小写
import re
lylic='Words.......'
lylic.lower()
(符号)替换
lylic=re.sub('[进行替换的对象],'替换成什么',对谁操作)
词频的统计
dic={i:word.counts(i) for i in word}
Q: 自定义函数有什么用?
A: 重复性高的东西封装起来,重复用时直接调用
Q: 为什么有了自定义函数还要搞类呢?
A: 因为类可以封装更多东西,函数
方案1:1min多,在set() 除去重复词花了大量时间
方案2:不用集合用字典,1sec即完成
for word in words:
破折号-是个特殊字符:本身表示从哪到哪
要么放在最后,要么用 \- 转译,才能被识别为破折号。
\ 反斜杠在Python中是个转义字符
故路径不认
要改成 斜杠 / 或 双反斜杠 \\
常用的文件操作是 r (读) w(写)
set()
集合:元素不重复,无序
因字典的键是其凭据,不能修改,故要用不可变的数据类型(如字符串,数值,元组)来充当键。
字典里的元素无序,故不能用顺序索引,而要用键来索引。
字典:无序的数据类型?
由键值对构成
字符串是稳定的数据类型
不可修改,但可索引和切片
不同对象有不同方法(函数)
如列表有append,字符串没有,却有split
用两层循环实现冒泡排序:
x = [ ... ]
for i in range(len(x)) :
for j in range(i) :
if x[j] > x[i] :
x[j],x[i] = x[i],x[j]
print(x)
用列表推导式,一行命令求解曲边图形面积:
n=..
width = math.pi*2/(n-1) #因为默认从0开始,会失去第一个值,故实际只有n-1个矩形
S = sum( [abs(math.sin(i*width))*width for i in range (n)] )
列表推导式:
y = [ i for i in range(10) if i%2 == 1]
i : 要打印的内容
后面:对i的解释
比For循环效率高,但仍慢。
索引是一个左闭右开的区间
lower








